ARTIKEL PENGANTAR STATISTIKA
"Sebaran Peluang Kontinu"
(melengkapi tugas pengantar statistika IV)
disusun oleh:
Noviansyah Dwi Jaya
28114063
2KB04
SISTEM KOMPUTER
FAKULTAS ILMU KOMPUTER
UNIVERSITAS GUNADARMA
DISTRIBUSI
PELUANG KONTINYU
Berbeda dengan variabel
random diskrit, sebuah variabel random kontinyu adalah variabel yang dapat mencakup
nilai pecahan maupun mencakup range/ rentang nilai tertentu. Karena terdapat
bilangan pecahan yang jumlahnya tidak terbatas, kita tidak dapat menuliskan
semua nilai yang mungkin bersama dengan probabilitasnya masing – masing dalam
bentuk tabel. Namun dipakai fungsi kepadatan probabilitas (Probability Density
Function : pdf). Plot untuk fungsi seperti ini disebut kurva probabilitas dan
nilai probabilitasnya dinyatakan sebagai luas suatu kurva yang bernilai
positif.
Distribusi Peluang
Kontinyu terbagi menjadi:
- Distribusi Seragam Kontinyu
- Distribusi Tipe Gamma
- Distribusi Gamma
- Distribusi Eksponensial
- Distribusi weibull
- Distribusi Tipe Beta
- Distribusi Normal
1 . Distribusi Seragam Kontinyu

2. Distribusi Normal


3. Distribusi Eksponensial


URAIAN
PENGGUNAAN TABEL
Cara Penggunaan Tabel Z
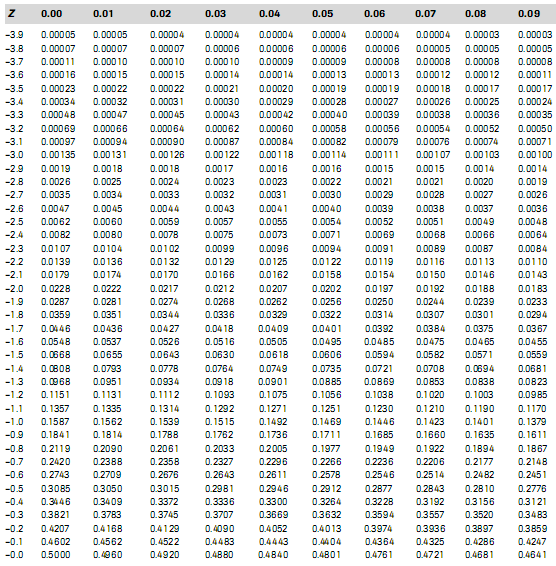
Contoh penggunaan:
Hitung P (X<1,25)
Penyelesaian: Pada tabel, carilah angka 1,2 pada kolom paling kiri. Selanjutnya, carilah angka 0,05 pada baris paling atas. Sel para pertemuan kolom dan baris tersebut adalah 0,8944.
Dengan demikian, P (X<1,25) adalah 0,8944.

Cara Penggunaan Tabel t
Uji T ini sering digunakan untuk mengetahui
apakah dalam model regresi variable independen (X1, X2, … Xn) secara parsial
berpengaruh signifikan terhadap variable dependen (Y). artinya dalam regresi table
ini sering dijadikan sebagai patokan untuk menentukan variable maupun konstanta
dari model yang didapat dari analisis regresi apakah signifikan atau tidak.
a

Menentukan derajat bebas atau
degree of freedom (df) dalam regresi
Dalam
pengujian hipotesis untuk model regresi, derajat bebas ditentukan dengan rumus
Df
= n – k
Dimana
n = banyak observasi sedangkan k = banyaknya variabel (bebas dan terikat).
Pada analisis regresi
digunakan probabilitas 2 sisi, Misalnya dicari nilai table distribusi t dicari
pada a = 5%: 2 = 2,5% (uji 2 sisi) dengan derajat kebebasan (df) n-k atau 18-3
= 15 (n adalah jumlah kasus dan k adalah jumlah variabel independen). Dengan pengujian
2 sisi (signifikansi = 0,025) hasil diperoleh untuk t table sebesar 2,131 atau
dapat dicari di Ms. Excel dengan cara pada cell kosong ketik = tinv(0.05,15) kemudian tekan Enter.
Cara Penggunaan Tabel F
Dalam
pengujian hipotesis, tentukan terlebih dahulu tingkat/taraf signifikasnsi
pengujian kita (biasanya disimbolkan dengan a (alpha). Misalnya 1%, 5%, 10% dan
seterusnya. Nah, taraf/tingkat signifikansi tersebut yang merupakan
probabilitas yang akan kita gunakan dalam mencari F Tabel. Pada kasus ini kira
akan mencari F table menggunakan 5%
DERAJAT KEBEBASAN (DEGREE OF
FREEDOM)
Derajat
kebebasan mempunyai dua makna yag berbeda. Dalam kaitannya dengan distribusi statistic
untuk memberikan nama dari salah satu parameternya. Dalam kaitannya denga
kecocokan model, derajat kebebasan menunjukan pada jumlah informasi yang
independen yang ada digunakan untuk membuat estimasi terhadap informasi yang
lain. Umumnya kita memulai jumlah derajat kebebasan dengan data. Semakin suatu
prosedur atau model cocok, maka jumlah derajat kebebasan semakin kecil.
Penghitungan derajat kebebasan dilakukan melalui ukuran sampel. Derajat kebebasan merupakan pengukuran
jumlah informasi dari data sample yg telah digunakan. Setiap penghitungan statistic
dilakukan dari suatu sampel tertentu, maka satu derajat kebebasan digunakan.
Setiap rumus dalam SPSS cara menghitung derajat kebebasan (DF/Degree of Freedom)
berbeda, misalnya dalam Chi Square untuk menghitung DF digunakan rumus (C-1)x(R-1);
sedang untuk uji b sampel bebas untuk menghitung DF digunakan rumus n-2; untuk
uji t sampel berpasangan untuk menghitung DF digunakan rumus n-1 dstnya.
Rumusnya mencari F table adalah
sebagai berikut :
Df1=k-1
Df2=n-k
DImana
:
k
: adalah jumlah variabel (bebas + terikat)
n
: adalah jumlah observasi/sampel pembentukan regresi
Contoh:
Kita
menggunakan study kasus yang ada disini, dipostingan saya tentang Analisis
Regresi Linear Berganda Dengan SPSS.
Pada
studi kasus tersebut kita melihat bahwa jumlah variabel bebas/independent ada 3
dan jumlah variabel terikat/dependet ada 1.
Berdasarkan
rumus derajat bebas diatas didapatkan
Df1
= 4-1 = 3
Df2
= 38-4 = 34
Sehingga bias kita
lihat dalam table seperti ini.
